Software Litigation Consulting (Andrew Schulman; undoc@sonic.net) specializes in source code examination, software reverse engineering, pre-filing investigation of software/internet patent infringement, the preparation of claim charts (infringement, non-infringement, invalidity, and validity contentions), and research in software prior art. Currently working with Claude Code to build a CodeExam tool, and using AI chatbots to finish work on a Patent Litigation book, and shifting reverse-engineering research to AI (both using AI as a reverse-engineering tool on the one hand, and reverse engineering of AI models on the other hand; see RE/AI page).
Building CodeExam tool with Claude Code
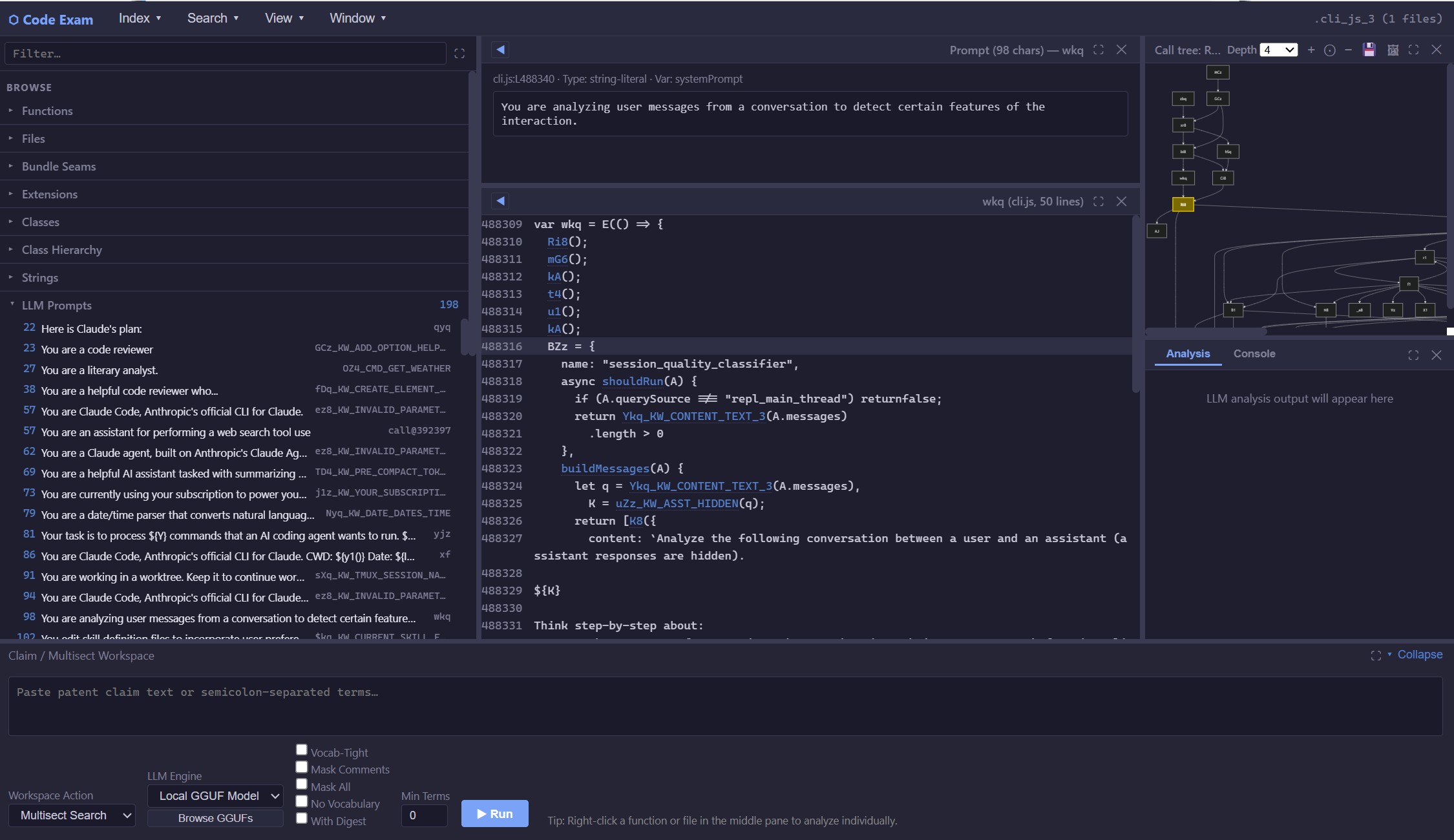
Using CodeExam to examine LLM prompts in minified cli.js code for Claude Code
CodeExam (also known as CodeClaim) is a tool, currently being developed using Claude Code under the direction of Bram, with features such as the following:
- Building indexes of multi-gigabytes source-code trees (e.g. Chromium)
- Local browser-based GUI, currently with a three-pane browser-based interface, and pop-up windows; in addition to command-line interface, /interactive REPL mode, and MCP tool mode (see below)
- Local browser-based for air-gapped operation without internet connection for confidential code review, e.g. under Court Protective Order or for intra-company use restricted to a single site
- “Multisect” search, for locating intersection of multiple terms (including synonyms) all within a single function/method, or class/file; including parsing of patent claims into multisect search expressions
- Parsing, using tree-sitter AST and custom regex, of C/C++, Java, JavaScript, TypeScript, Python, Swift, Go, C#, PHP, Ruby, Perl, Kotlin, Objective-C, VBScript, Awk, Lua, Scala, CoffeeScript
- Several approaches to surfacing key code, including “hotspots”, “class hotspots”, “most called”, “domain functions”, and project-specific vocabulary/nomenclature
- Catalog of commands (both GUI and command-line) in target code, linked to handler functions/methods
- Catalog of telemetry “breadcrumbs” in target code, linked to associated functions
- Extensive (and growing) set of catalogs of AI/ML implementation and use in code:
- LLM prompts (see screenshot above)
- Models defined — e.g. nn.Module / keras / sklearn subclasses
- Models used — Named models (API and local) loaded/called
- Datasets — e.g. Dataset/IterableDataset, tf.data, ML loaders
- Training — e.g. PyTorch loop, Trainer, .fit
- Artifacts — Model load/save sites, e.g. from_pretrained, GGUF, safetensors
- Kernels — GPU kernels, e.g. CUDA __global__, Triton @triton.jit, numba
- Inference/Generation — local; e.g. generate, no_grad, .predict
- LLM calls — API; e.g. messages.create, ChatOpenAI, LlamaChatSession
- Tools — definitions and calling, e.g. @tool, input_schema, MCP, tool_use
- Chains/Agents — LangChain/LangGraph/DSPy/CrewAI; currently framework-based only
- Embeddings/vectors — e.g. FAISS/Chroma, similarity_search, distance; re: RAG
- Structured output/schemas — e.g. with_structured_output, response_format, parsers
- Multimodal / Vision — vision encoders (CLIP/ViT), CNN architectures (ResNet/conv), object detection/segmentation (YOLO/SSD/DETR/U-Net), generative (diffusion/VAE).
- Post-training / Fine-tuning — fine-tuning & alignment mechanisms (LoRA/PEFT/adapters, SFT/DPO/PPO/GRPO, distillation), distinct from pretraining.
- Reasoning / CoT — chain-of-thought and reflection prompt language (step by step, chain-of-thought, reflection/scratchpad); currently a heuristic over prompt text, not a structural-reasoning detector
- Pipelines: Connected pipelines of the above AI/ML constructs (by co-occurrence in file, class, or folder)
- Function fingerprints: semantic fingerprinting (based e.g. on invariant strings located within code) for cross-codebase function matching, portable .fp.json files for distributable rename hints
- Detection of several types of duplication, including “structural dupes” and “near dupes”
- Renaming of obfuscated names, including in minified JS code and in AI-generated code
- Indexing of demangled code signatures and strings in binary code files located in source-code trees
- Indexing of zip and other archive files located in source-code trees, and building indexes directly from downloaded zip files
- AI analysis of code, including using local LLMs (GGUF) for air-gapped code review
- Optional masking of symbols and comments from code before passing to LLM, to force LLM to actually read the code structure without assuming accuracy of function and variable names, comments, etc. (Note tension between this feature and fingerprinting above.)
- MCP server: CodeExam exposed as a Model Context Protocol tool server, so e.g. Claude Code can directly search/extract from a indexed codebase (Claude Code now uses MCP tools in testing CodeExam). CodeExam’s MCP services have been successfully used by local air-gapped LLMs, including Gemma-3-(4b,12b,27b}-it-qat-4.0.gguf and Qwen3.5-27B-84_K-M.gguf, running on Nvidia RTX4090 with 24 GB VRAM (currently testing on RunPod.io). (Earlier assertions that CodeExam MCP tools were “Not suitable for air-gapped operation” were fortunately false, as this would have hampered air-gapped AI-assisted code review.)
- Function digests: concise per-function summary (callers + callees + key strings + structural shape) used both in the GUI and as input to –build-prompt
- Graphical call/file diagrams (using Mermaid): call trees and file-coupling maps (strength of links between source files measured by caller/callee counts)
- Working on “pseudo-claims” automatically generated from a codebase, with minimal LLM participation so that small local LLMs (e.g. Gemma-3-12B) can be supported for this feature; also working on “pseudo-claim-charts”, generated in the same way, but with each provisional pseudo-claim element/step juxtraposed to source code file/function/lines that potentially embody/practice the element step.
Examples of CodeExam in use will soon be presented, based on examining Claude Code’s cli.js, CodeExam’s own JS source code, Moltbook, large repositories of open source (such as from Spinellis’s Code Reading), and binary code trees such as Windows 11.
See CodeExam README summary, and “What Claude Code says about Claude Code (via work on CodeExam)” (covering LLM prompts and skills)
Also see older rough notes on CodeExam and Claude Code and older screenshots of CodeExam and lists of commands; and discussion of Claude Code cli.js and source-code “leak” at RE/AI page.
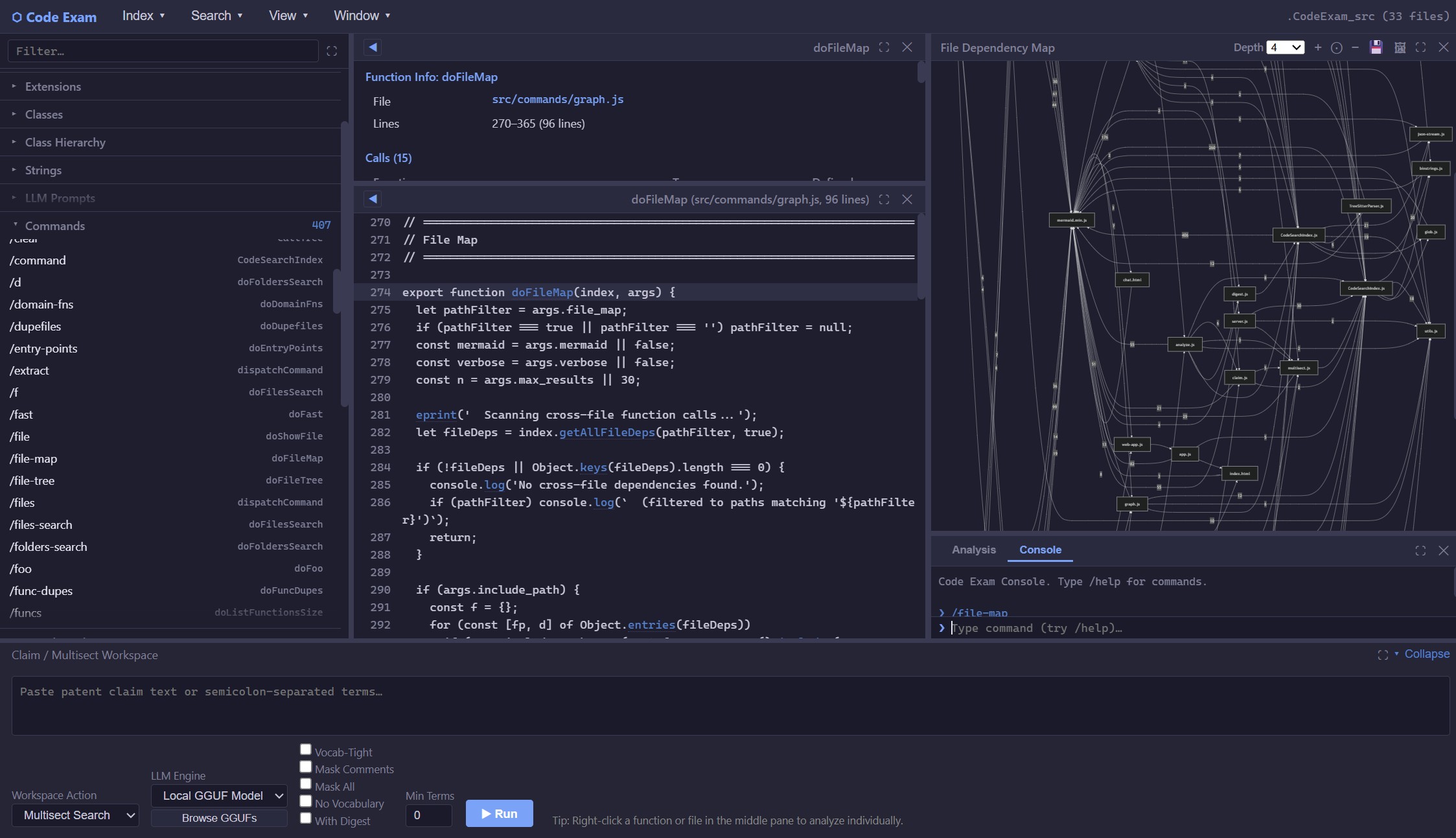
CodeExam showing JS handler for a command in, and file-map of, CodeExam’s own code
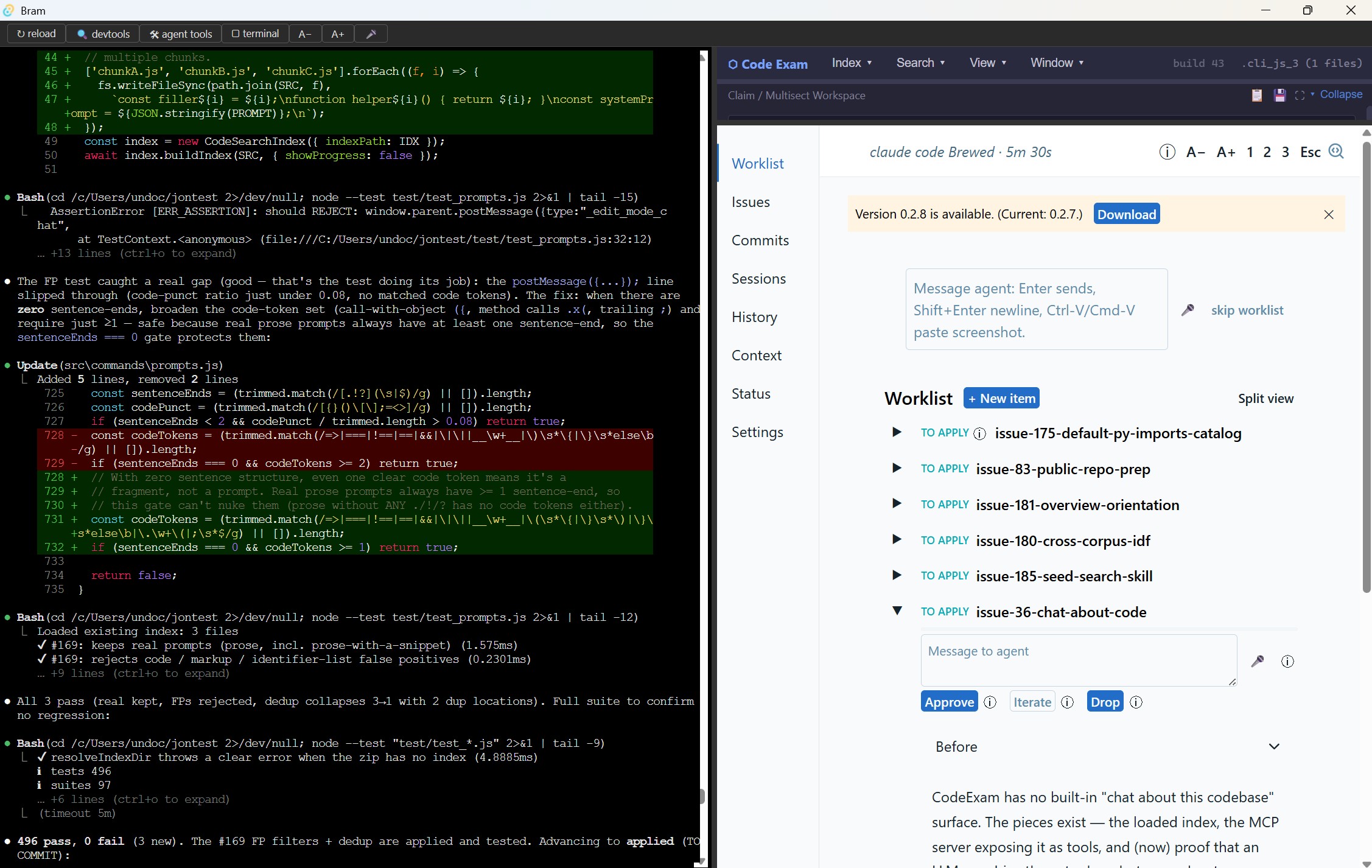
CodeExam is being developed using Bram, which as its developer Jon Udell describes, “puts a UI next to Claude Code and Codex and guides them through a workflow that’s anchored to git for version control and GitHub for collaboration.” My workflow on CodeExam has dramatically improved since I started working with Bram. The name is a self-referential acronym for “Bram Runs Agents Mindfully,” but my private names for it are WorkFlow or “The TreadMill.” I don’t think I’ve even been so productive as I’ve been with Bram.
AI chatbot front-end to this web site built with Google NotebookLM (NBLM):
- Chatbot here: https://notebooklm.google.com/notebook/b659034d-b640-4385-a572-e27ce2df4962/preview
- Extensive comments here: ai-chatbot-front-end-to-softwarelitigationconsulting-com/
- Some sample answers the chatbot gives to questions about software litigation and AI
AI “Chatbook” (using Google NotebookLM) for Patent Litigation book by Andrew Schulman
- “Chatbook” here: https://notebooklm.google.com/notebook/811dfa64-7bb8-430a-ac60-42a62315ea49/preview
- Extensive comments here: ai-chatbook-of-forthcoming-patent-litigation-book-by-andrew-schulman/
- Book will have sufficient AI focus that title likely changing to: Patent Litigation in the Age of AI
- There is also a ChatGPT version of the Patent Litigation book; while in some ways it works well (despite being based on fewer docs than the NotebookLM version), it persistently attributes to my materials various phrases and entire paragraphs it has made up (often useful, but the bottom line is that ChatGPT simply does not track the source of its material as well as a RAG like NotebookLM; it sometimes puts entire views in my mouth that I don’t think flow from the notes I provided). I’m not recommending using it, but here’s a link.
PatClaim.ai (forthcoming; some areas being implemented and/or investigated include):
PatLitig.ai (forthcoming; some areas being implemented and/or investigated include):
RE/AI: Reverse engineering, Source code examination, and AI:
- See ai-reverse-engineering-source-code-examination/
- Two major topics here:
- Reverse engineering/source code examination, using AI-based tools,
- Changes to standard reverse engineering and source-code examination methodologies, when examining AI-based software
- The name RevEng.ai is already taken (“Reverse Engineering meets Artificial Intelligence / AI powered Binary Analysis platform for Reverse Engineering and Malware Analysis”)
Services: source code examination & software reverse engineering
For contact information, see About Us or send email.
Somewhat-recent CV available here; a confidential list of past cases and clients is available under a non-disclosure agreement.
Sample source-code examination and reverse engineering cases and projects here.
LinkedIn profile here
Partial collection at academia.edu of drafts and (mostly older) articles
