The chain of thought (CoT) details panels shown below appeared in the chats described in Sessions with ChatGPT on modeling patent claims/litigation and on reverse engineering AI models. Other CoT details are shown in additional pages on this site, including those on walking neural networks, Part 1 and Part 2.
In ChatGPT, clicking on a blurb like “Thought for 16 seconds” displays the “Details” panel on the right-hand side.
It’s open to question whether these prose statements — even if appearing in real time over the course of 16 seconds while the user waits for the AI chatbot’s response — accurately reflect an internal stream of reasoning steps. The ones I’ve seen from ChatGPT appear to be linear, without back-tracking, for example, and without rejection of multiple options. Though perhaps that is the actual stream. CoTs from DeepSeek with e.g. “Wait, no” (see below) may reflect rejection of previous steps.
A user’s CoT prompts (including “Let’s think step-by-step”) can improve LLM accuracy; see the section “Chain-of-Thought: Think Before Answering” in the Prompt Engineering chapter of the superb O’Reilly book, Hands-On Large Language Models by Jay Alammar and Maarten Grootendorst (2024), though the prompt may perform more as additional text that the LLM uses as part of its next-word prediction mechanism, and less as an instruction as such.
That is somewhat separate from the issue discussed here, which is what we are to make of the unprompted CoT streams shown by AI chatbots; certainly users shouldn’t assume that the chatbot’s CoT output reflects introspection. [[TODO: add references to how “reasoning models” are being implemented with e.g. reinforcement learning (RL), e.g. Nathan Lambert’s “Quick recap on the state of reasoning” (2025) and his “Why reasoning models will generalize” (2025); also see the page here on Claude’s ability to analyze data using instruction tuning.]]
See research paper by Turpin et al., “Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting” (2023).
See article discussing the use of human-interpretable prose in CoT: “When working through a problem, OpenAI’s o1 model will write a chain-of-thought (CoT) in English. This CoT reasoning is human-interpretable by default, and I think that this is hugely valuable. Assuming we can ensure that these thoughts are faithful to the model’s true reasoning, they could be very useful for scalable oversight and monitoring. I’m very excited about research to help guarantee chain-of-thought faithfulness. However, there’s a impending paradigm for LLM reasoning that could make the whole problem of CoT faithfulness obsolete (and not in a good way).” The impending paradigm is that described in a paper from Meta researchers on COCONUT (Chain of Continuous Thought).
See “Example of lengthy DeepSeek chain of thought” for a 55 sec. CoT, including many apparent self-cautions to “Wait,…” “Wait, no…” and “But…”.
In an interesting article on DeepSeek’s costs and export controls, Dario Amodei of Anthropic has noted: “I suspect one of the principal reasons R1 gathered so much attention is that it was the first model to show the user the chain-of-thought reasoning that the model exhibits (OpenAI’s o1 only shows the final answer). DeepSeek showed that users find this interesting. To be clear this is a user interface choice and is not related to the model itself.”
But see “Local small (8B) distilled DeepSeek produces nutty CoTs” at the end of this page.
Lex Fridman has a nice riff on chains of thought and reasoning (from ChatGPT o1 Pro vs. Google Gemini 2.0 Flash Thinking vs. DeepSeek-R1) in an intermission to his 5 hr. interview with Nathan Lambert and Dylan Patel on DeepSeek (transcript).
OpenAI’s “Deep Research” feature provides a chain of thought as it gathers and synthesizes information from various sources. For example, I asked ChatGPT-o3 mini with “Deep Research” enabled to give me both a theoretical (e.g. research papers) and practical (e.g. Python libraries) overview of the TREPAN algorithm for extracting symbolic rules (decision trees) from trained neural networks. In addition to providing a detailed, useful-looking overview, its chain of thought showed reading papers from arxiv.org, and trying to access code in GitHub: “First, I looked into Craven and Shavlik’s 1996 NIPS paper on TREPAN, which extracts decision trees from neural networks using queries to approximate predictions. Then, I explored potential Python libraries for TREPAN…. I’m digging into GitHub repositories for TREPAN Python implementations, noting one for general purposes and another for regression tasks. Interestingly, TREPAN lacks a mainstream library, though open-source alternatives exist” (it then runs into login problems at GitHub, but the point for now is that it’s trying to actually synthesize results between papers and open-source code, though it does also look at Wikipedia). I’ll be writing more on OpenAI “Deep Research” soon; for now, see the end of this ChatGPT session on symbolic regression, TREPAN, and distillation — to see the CoT panel, search and click on the link at “Research completed in 3m · 14 sources” (the chat starts off very slowly with me asking for definitions of simple terms like transformer and attention, and then moves into neural-network formula extraction techniques, including TREPAN).
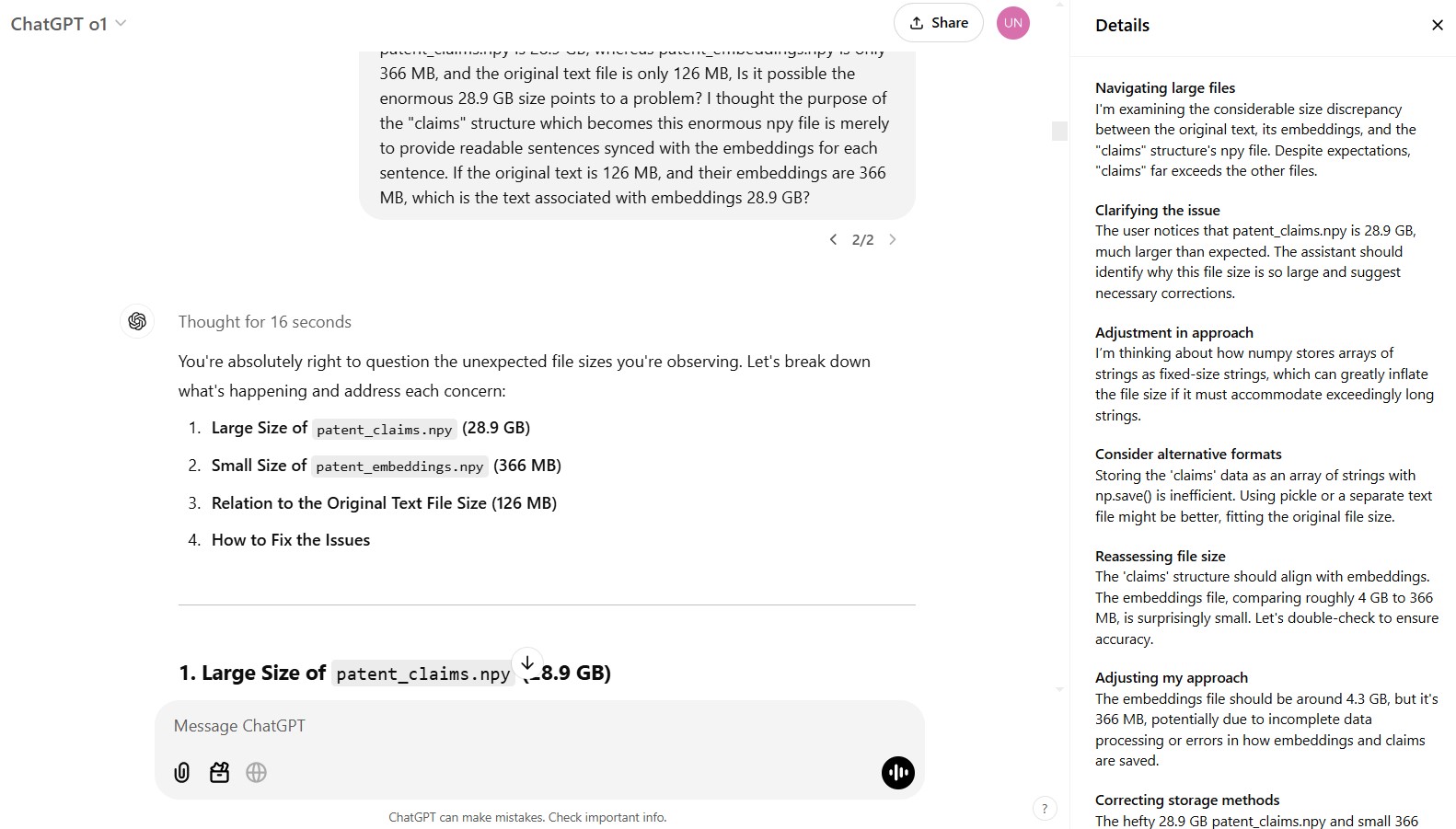
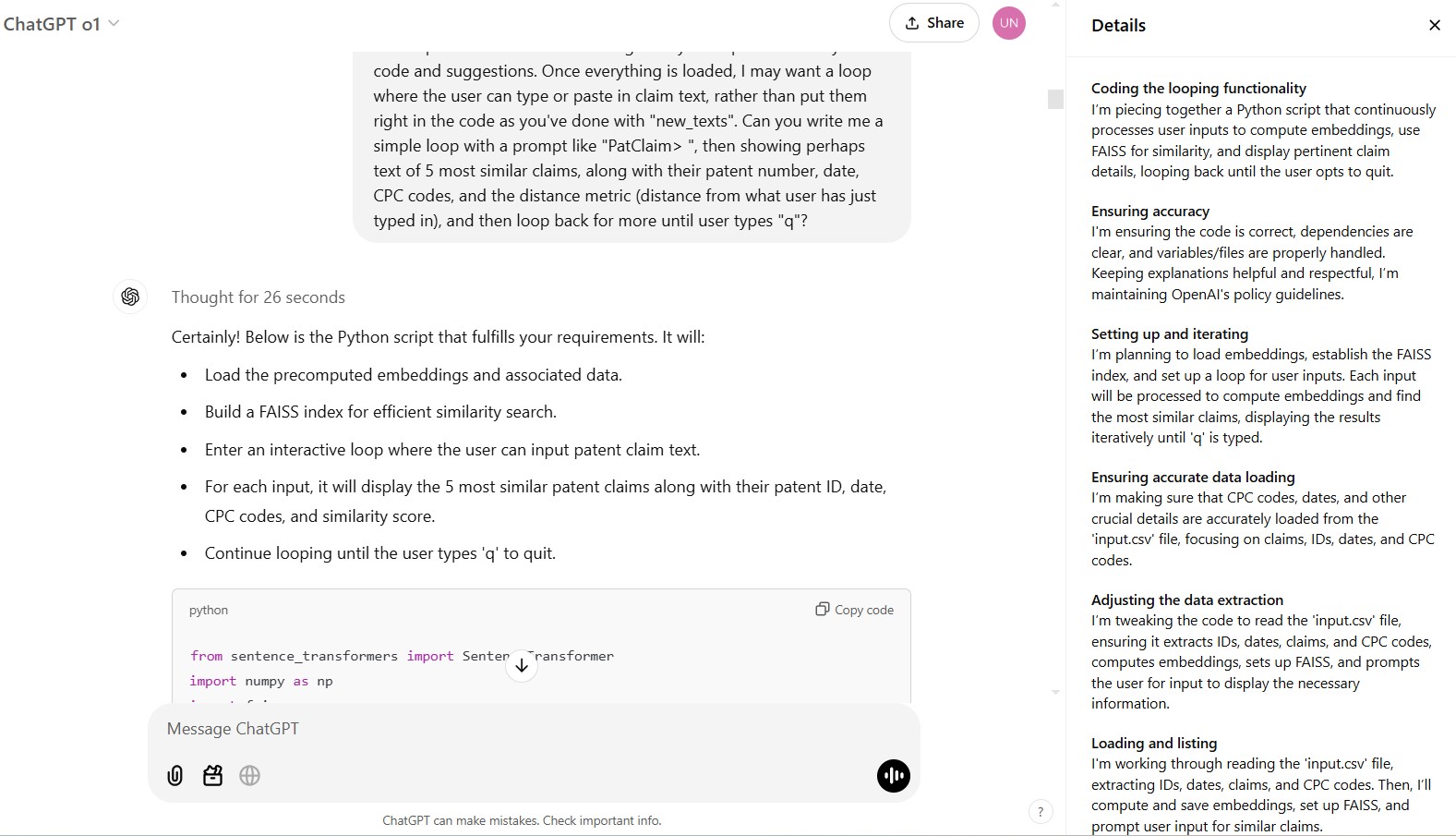
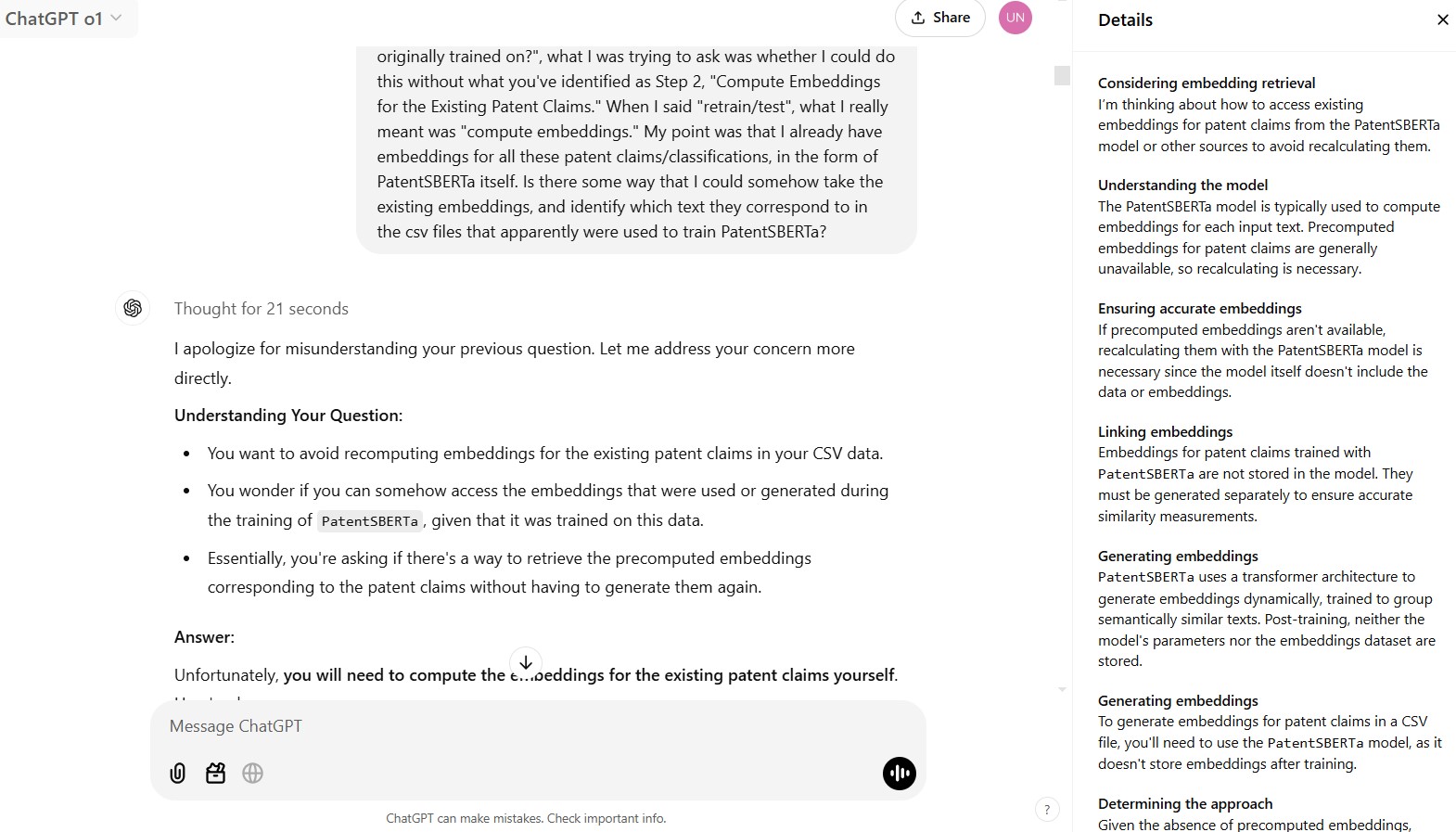
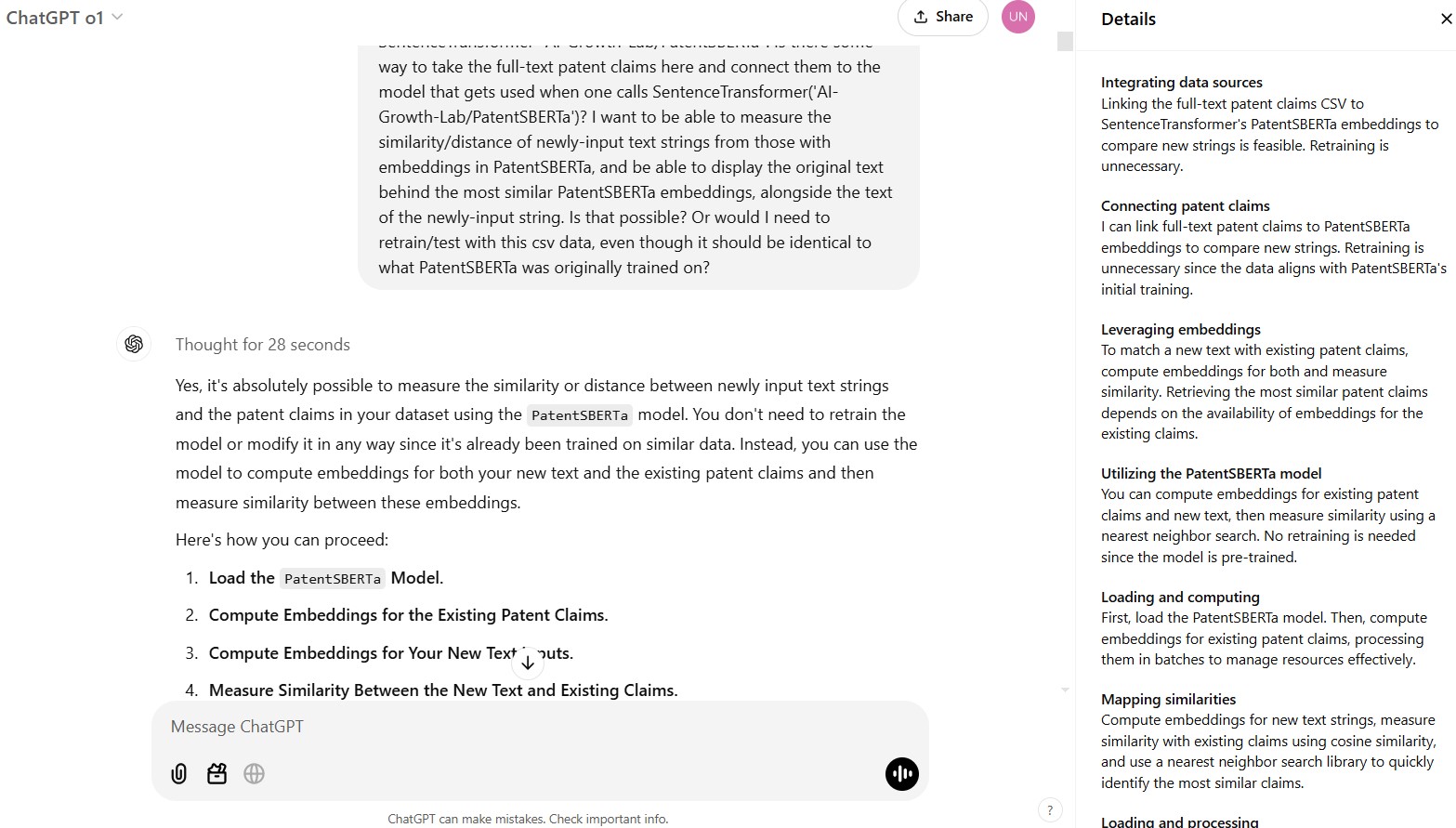
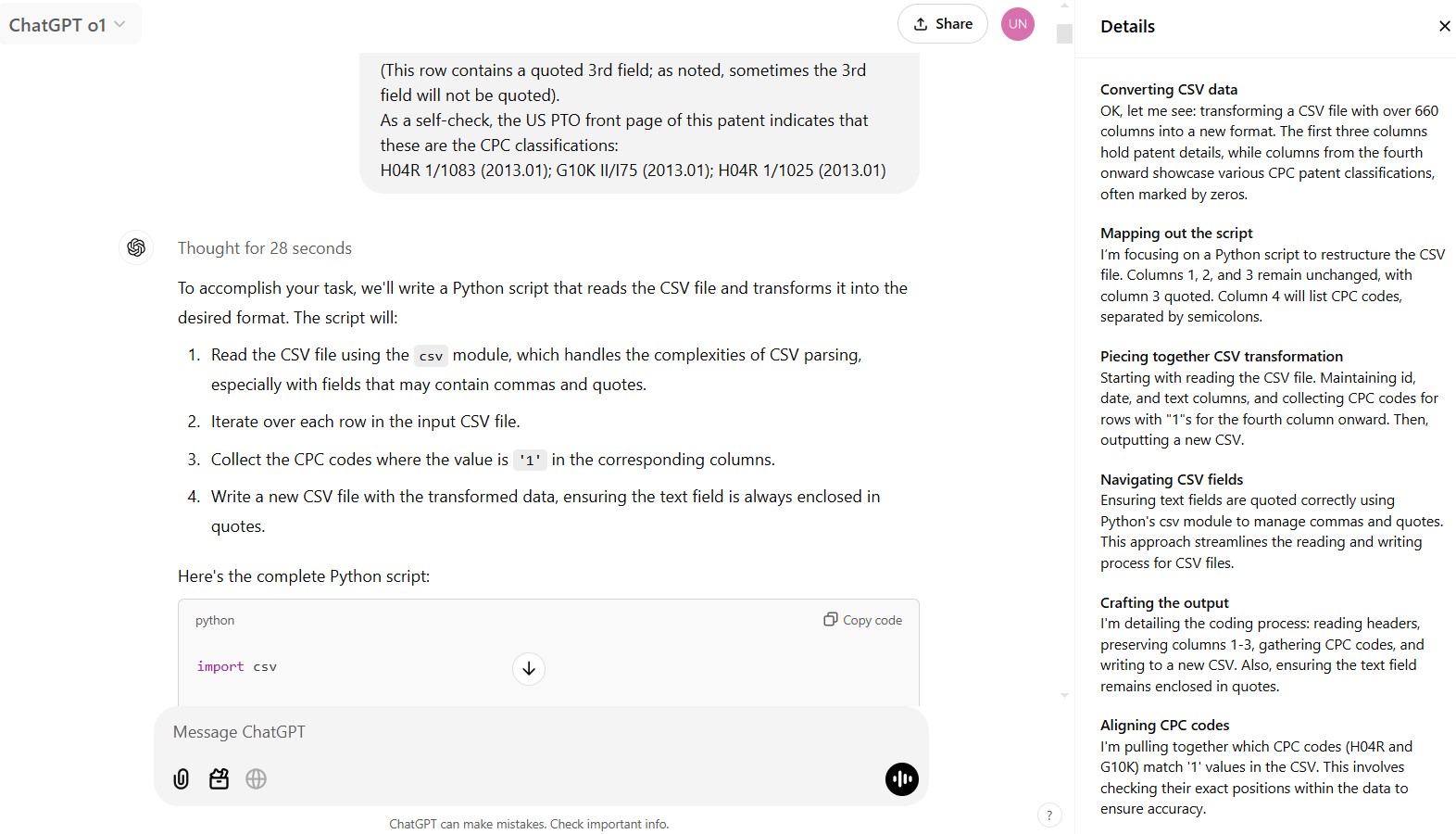
Thought for 28 seconds [a fairly pedestrian example, and 28 seconds is surprising for what sounds so straightforward, but useful to see how ChatGPT describes its “chain of thought”]:
Converting CSV data
OK, let me see: transforming a CSV file with over 660 columns into a new format. The first three columns hold patent details, while columns from the fourth onward showcase various CPC patent classifications, often marked by zeros.
Mapping out the script
I’m focusing on a Python script to restructure the CSV file. Columns 1, 2, and 3 remain unchanged, with column 3 quoted. Column 4 will list CPC codes, separated by semicolons.
Piecing together CSV transformation
Starting with reading the CSV file. Maintaining id, date, and text columns, and collecting CPC codes for rows with “1”s for the fourth column onward. Then, outputting a new CSV.
Navigating CSV fields
Ensuring text fields are quoted correctly using Python’s csv module to manage commas and quotes. This approach streamlines the reading and writing process for CSV files.
Crafting the output
I’m detailing the coding process: reading headers, preserving columns 1-3, gathering CPC codes, and writing to a new CSV. Also, ensuring the text field remains enclosed in quotes.
Aligning CPC codes
I’m pulling together which CPC codes (H04R and G10K) match ‘1’ values in the CSV. This involves checking their exact positions within the data to ensure accuracy.
Mapping and enhancing
The script is set to map ‘1’s to CPC codes, extract specific fields, and output a refined CSV, all while managing the large dataset efficiently.
Revising the script
I’m making tweaks to ensure ‘1’s map to CPC codes, text fields are quoted, and output is efficient. This approach balances accuracy with performance.
Ensuring accurate text quoting
I’m curious about the ‘csv’ module’s ‘quoting’ parameter to verify that text fields are consistently quoted in the output CSV, enhancing accuracy as requested.
Example of lengthy DeepSeek R1 chain of thought (“Thought for 55 seconds”)

[Hard to say if DeepSeek is really talking to itself here (and would it be doing so in English, or in any other human language?), but I like the “Wait,…” “Wait, no…” and “But…” below. See Nathan Lambert’s “DeepSeek R1’s recipe to replicate o1 and the future of reasoning LMs” (Jan. 21, 2025)
AS: You’ve told me that your training cutoff is July 2024, and that you don’t know about DeepSeek-V3, released Jan. 2025. However, I have a related question which you can perhaps answer as a matter of general knowledge, or perhaps from knowledge of DeepSeek-R1. The DeepSeek-V3-Base folder on HuggingFace contains 163 *.safetensors files (with filenames such as “model-00001-of000163.safetensors”), totaling about 687.9 GB in size. Would that generally define the size of a local installation on my laptop, for example? Would I need to download all 163 *.safetensors files?
DeepSeek R1:
Thought for 55 seconds
Okay, let me try to figure this out. The user is asking about the size of a local installation for the DeepSeek-V3-Base model, which has 163 safetensors files totaling around 687.9 GB. They want to know if they need to download all those files for a local setup on their laptop.
First, I remember that when models are stored on HuggingFace, they often split large files into smaller parts. This is probably to make downloading easier, especially with potential interruptions. So each of those 163 files is a part of the whole model. But when you actually use the model, you don’t need all the parts at once, right? Wait, no. When loading the model, the framework (like PyTorch or TensorFlow) usually expects all the parts to be present because they contain different portions of the model’s parameters. So if the model is split into 163 files, you do need all of them to load the model correctly.
But wait, sometimes checkpoints are saved in multiple files, but maybe each file is a different layer or component. But in reality, frameworks like HuggingFace Transformers handle the loading by combining all the split files. So the total size on disk would indeed be the sum of all the parts because each file is a necessary piece of the model. So the user would need all 163 files, and the total disk space required would be around 688 GB. That’s a lot for a laptop.
But maybe there’s a misunderstanding here. Some models have different formats. For example, sometimes safetensors files are sharded, meaning they split the tensors across multiple files. So if the model is 688 GB, that’s the size of the parameters in half-precision (like float16 or bfloat16). Each parameter is 2 bytes, so 688e9 * 2 bytes would be… Wait, no.
But maybe there’s a misunderstanding here. Some models have different formats. For example, sometimes safetensors files are sharded, meaning they split the tensors across multiple files. So if the model is 688 GB, that’s the size of the parameters in half-precision (like float16 or bfloat16). Each parameter is 2 bytes, so 688e9 * 2 bytes would be… Wait, no. Wait, the number of parameters can be calculated. If the model is, say, 7B parameters, each parameter in float16 is 2 bytes. So 7e9 * 2 bytes = 14e9 bytes = ~14 GB. But this model is 688 GB. That would imply the model has 688e9 / 2 = 344 billion parameters, which is way larger than any existing model. Wait, that can’t be right. So maybe the model is stored in a different format. Wait, maybe it’s stored in 32-bit floats instead of 16-bit? Then each parameter is 4 bytes. 344e9 parameters would be 1.376e12 bytes, which is about 1.376 TB. But the total here is 688 GB, so maybe it’s stored in 16-bit. Wait, 688 GB is 688 * 1e9 bytes. Divided by 2 bytes per parameter (for 16-bit) gives 344e9 parameters. That’s 344 billion parameters. That’s huge. But models like GPT-3 are 175B parameters. So 344B would be even larger. Maybe there’s a mistake here. Alternatively, maybe the files are stored with redundancy or include other data like optimizer states? But no, the safetensors files typically just contain the model weights.
Wait, perhaps the user is confusing the total size. Let me check: 163 files totaling 687.9 GB. So each file is roughly 4.22 GB (687.9 / 163 ≈ 4.22). That seems plausible for sharded model weights. But the model size in parameters would depend on the data type. For example, if it’s a 344B model in 16-bit, that’s 688 GB. But that’s a very large model. Alternatively, maybe the model uses quantization. But if it’s the base model, it’s probably in float16 or bfloat16.
But regardless of the parameter count, the user’s main question is: do they need all 163 files for a local install. The answer is yes. When a model is sharded into multiple safetensors files, you need all of them to load the model because each contains a portion of the model’s tensors. The HuggingFace transformers library, for example, automatically handles loading all the shards when you use `from_pretrained()`. So the total disk space required would be the sum of all shards, which is ~688 GB. That’s a massive amount for a laptop, both in terms of download and storage.
However, maybe the user is looking at a specific version or there’s a mistake. For instance, sometimes repositories might have multiple branches or versions, and the 163 files could include different checkpoints or something else. But if it’s the model itself, then yes, all shards are needed. Alternatively, maybe there’s a different format available, like a single file or a quantized version that’s smaller. The user should check the repository for alternative formats or quantization options. If not, they’d have to download all files.
Another point: safetensors is a secure alternative to pickle, but the number of files doesn’t change the total size. So regardless of the number of shards, the total size is the same. So the local installation would require approximately 688 GB of space. That’s a lot, but maybe the model is intended for enterprise use with high-resource systems, not personal laptops.
In summary: Yes, all 163 files are necessary, and the total local installation size would be around 687.9 GB. Unless there’s a quantized or smaller version available, the user would need all shards. For a laptop, that’s impractical, so they might need to look for a smaller model or use cloud services.
[And now DeepSeek provides the answer:]
To use the DeepSeek-V3-Base model locally, you would indeed need to download all 163 .safetensors files , as they collectively contain the model’s weights. The total size of ~688 GB reflects the full unquantized model in its original precision (likely 16-bit or 32-bit floats) . Here’s a breakdown: [followed by a considerably shorter explanation for the user; the same PDF contains an additional DeepSeek CoT example, and see here for further examples.]
Local small (8B) distilled DeepSeek produces nutty CoTs
Running as a small local model, “deepseek-ai/DeepSeek-R1-Distill-Llama-8B” has produced some truly ridiculous CoT text on my laptop. I’ll describe this in more detail a separate page on examining DeepSeek. As an example, when I asked “what is the french word for dog?”, DeepSeek-R1-Distill-Llama-8B fell into a stream of consciousness like “I’ve heard a bit of French before, but I’m not entirely sure. Let me think about how I learned French in school. Wait, in my French class, we went over the names of animals….” and more in the same spirit. After once giving a concise answer to “what is water made of?”, the next time it thought it needed a lengthy CoT including “Hmm, I remember from school that water is H2O, but I’m not entirely sure what that means. Let me think. H2O is like a chemical formula, right? So H stands for hydrogen and O stands for oxygen. But how does that translate into water being a liquid?” and on for three more paragraphs.
I uploaded some of this to DeepSeek-R1 online, and it sought to explain DeepSeek-R1-Distill-Llama-8B’s CoT “feels overly literal or verbose compared to mine”:
- Overthinking in R1-Distill: The DeepSeek-R1-Distill-Llama-8B model seems to “overthink” its responses, spending too much time on trivial details (e.g., explaining basic concepts like hydrogen bonding or French pronunciation) rather than focusing on the core task. This could be a side effect of its distillation process or training objectives….
- Creative vs. Literal Thinking: The R1-Distill model seems to struggle with balancing creative and technical thinking, often defaulting to overly literal or mechanical explanations. DeepSeek-V3, on the other hand, appears better at blending creativity with precision…
See also lengthy page analyzing some DeepSeek source code (using Google Gemini 2.0 Flash Experimental), which has a section at the end on running DeepSeek-R1-Distill-Llama-8B locally, and on its odd CoT.
